
Client Success Story: NOZ Digital bringt mit BotTalk Artikeln das Sprechen bei.

Seit April 2019 setzt NOZ MEDIEN die Text-To-Speech Audio Plattform BotTalk erfolgreich auf drei Webportalen - noz.de, svz.de und shz.de - und in ihrer mobilen App ein. Im Gespräch mit CEO & Founder Andrey Esaulov erklärt Patrick Körting (Head auf Audio, NOZ Digital) warum NOZ MEDIEN an BotTalk herangetreten ist, welche Auswahlkriterien es bei der Suche nach einem geeigneten Technologie-Partner im Bereich TTS gab, und warum der Umgang mit BotTalk für die Redaktion so einfach ist.
Andrey: Hallo Patrick! Bitte stelle Dich und deine Arbeit bei der NOZ vor.
Patrick: Mein Name ist Patrick Körting, ich bin seit Anfang 2019 bei NOZ Medien. Dort habe ich ursprünglich im Business Development angefangen. Meine Aufgabe war es zu überlegen, wie auf digitalen Wegen und, vor allem, betrieben durch Technologie, in den nächsten fünf bis zehn Jahren Geld verdient werden kann. Anfangs habe ich mich mit sehr vielen Menschen bei NOZ Digital unterhalten. Zu diesem Betrieb gehören 42 Tageszeitungen, 60 Magazine und Werbeagenturen. Das ist ein großes Netzwerk von knapp 60 Firmen und ich habe mich mit verschiedenen Protagonisten und Stakeholdern ausgetauscht.
Ich habe geschaut vor welchen Herausforderungen sie stehen. Basierend darauf habe ich innerhalb der ersten anderthalb Monate circa. 20 Ideen entwickelt. Diese bin ich dann mit der Geschäftsführung durchgegangen.
Ich habe festgestellt, dass Content im Netz primär über den Audiokanal konsumiert wird, erst danach kommt das Thema Video und ganz unten Text.
Historienbedingt publiziert unser Haus jedoch Text, was auch in Ordnung ist, doch langfristig sollte man sich Gedanken machen, ob man auf das neue Nutzerverhalten nicht eingehen sollte. Somit kam die Frage: Wie kann man solche Inhalte hörbar machen?
Hier kommt die neue Text-To-Speech Technologie ins Spiel, die vielen durch Google Home oder Alexa bekannt ist. Wir reden jetzt über knapp 20.000 Artikel im Monat, die unser Haus publiziert.
Es wäre absurd dafür Sprecher zu buchen. So kamen meine zwei Leidenschaften zusammen: Automation und Technologie - und dabei neue Geschäftsfelder entwickeln.
Was sehr schön war - es hat sich durch Schicksalsfügung ergeben - dass zwei Kolleginnen, Anna Scholz und Lisa Kleinpeter, zeitgleich an einem Projekt gearbeitet haben, bei dem Podcasts eine Rolle gespielt haben. Das Thema Podcast war eher weniger auf meiner Agenda, weil ich eine große Faszination für Technologie hege. In mehreren Workshops, die ich eigentlich aus Business Development-Sicht unterstützt habe, ist uns irgendwann aufgefallen, dass es durchaus Sinn machen würde, wenn wir getrennt arbeiten.
Dies war eigentlich der Ursprung des Audio-Projekts, bei dem wir festgemacht haben, dass es zum einen die maschinelle/synthetische Vertonung gibt und wir zeitgleich neue Inhalte schaffen, die originär für Audio produziert werden. Aus dem einfachen Grund das Spektrum der Inhalte, die unsere Medienhaus bieten kann, breiter zu machen.
Somit hatten wir diese zwei sehr extremen Lager: auf der einen Seite extrem technologisch, voll automatisiert und auf der anderen Seite Podcast - der, neben Video, der teuerste und aufwendigste Produktionsbereich ist, den unsere Firma überhaupt hat.
Daraus ist dann ein dritter Bereich entstanden, der genau in der Mitte liegt. Das sind Hörartikel, also durch Journalisten vertonte Beiträge, in dem sie selbst ihre Artikel vorlesen. Zusätzlich haben wir noch Sprecher Agenturen gebucht um mehr Volumen zu bekommen. Doch dann stellte sich die Frage: Wo und wie kommt der Nutzer jetzt zu diesem Content?
Erst dann haben wir angefangen, uns mit der Integration in unsere eigenen Produkte zu beschäftigen, also solche Produkte, die schon Nutzer generiert haben. Diese technischen Produkte sind klassische Webportale, unsere News App und ein E-Paper. Dafür haben wir dann Konzepte entwickelt, um den Content dort zu integrieren. Irgendwann stellte sich natürlich die Frage: Wo sollen Smart Speaker aufgehangen sein, wenn nicht in diesem Projekt? So gab es dann einen zusätzlichen, komplett neuen Ausspielungskanal, den wir entwickelt haben.
Nach und nach merkt man es gibt viele Ideen, und häufig steht man vor technischen Herausforderung.
Der Aspekt "Technologie" ist immer größer geworden, sodass wir uns irgendwann entschieden haben eine eigene Technologie auf die Beine zu stellen, um das bedienen zu können. Ansonsten sind die Workflows so komplex, dass man Audio einfach nie lückenlos bedienen kann, ohne einen extrem hohen manuellen Aufwand.
Das widerspricht der gesamten Thematik Prozesse zu vereinfachen und, gerade bei Text-To-Speech, Prozesse zu automatisieren. Technologie war das neue Feld, dem wir uns dann eigentlich gewidmet haben und das nimmt in meinem Job einen sehr großen Teil ein.
Andrey: Warum seid ihr an BotTalk herangetreten, was war der Ausgangszustand?
Patrick: Die erste Anwendung, die ich überhaupt gesehen habe, abseits von Alexa und Google Home, war ein Angebot der NZZ, die, meines Wissens nach, die ersten waren, die Text-To-Speech umfänglich eingebaut haben. Ich mach das so ganz gerne: ich gucke mir das an, recherchiere bei LinkedIn und stalke die Leute so lange, bis ich sie am Telefon habe.
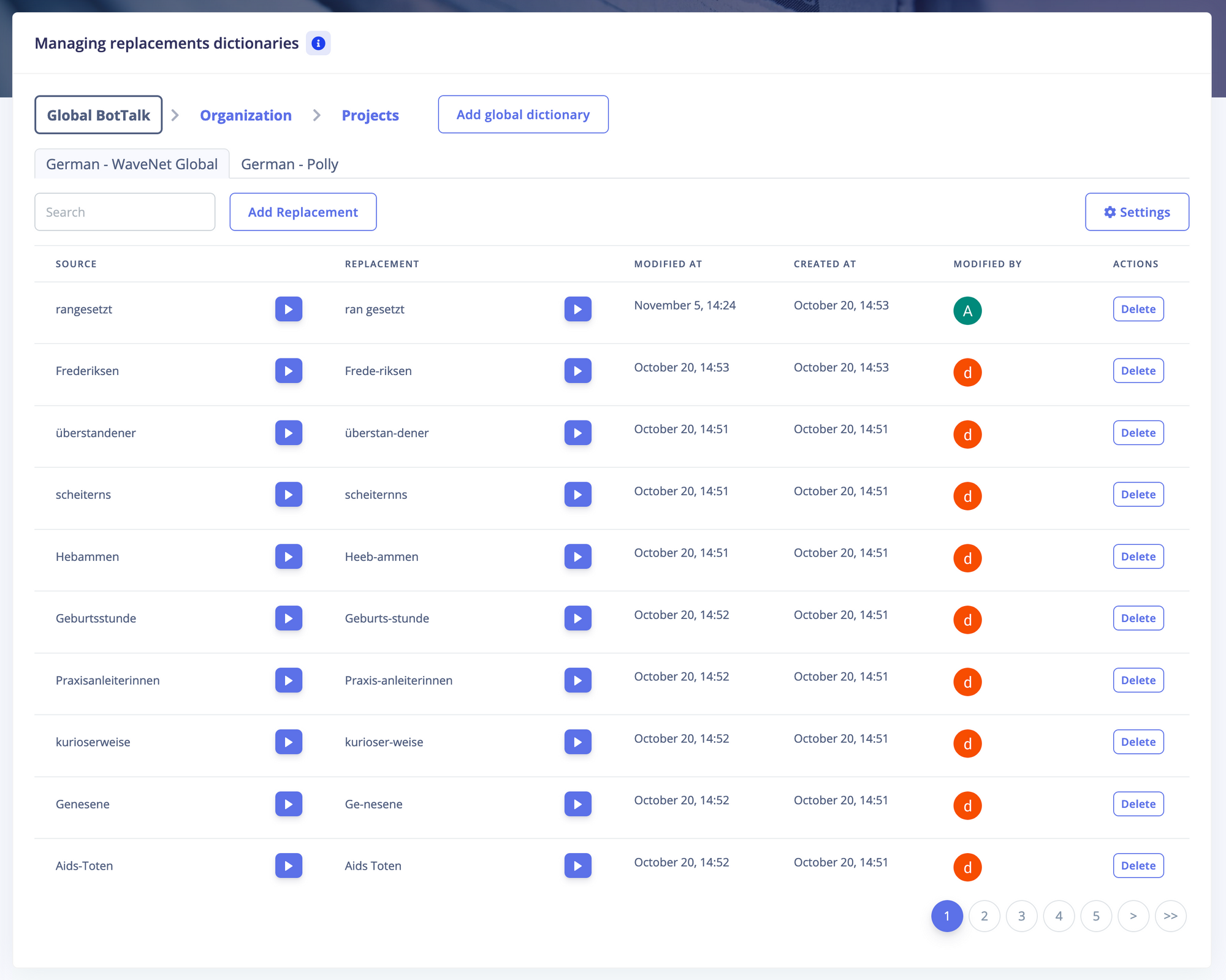
Zuerst habe ich gefragt, wie sie die Infrastruktur dafür aufgebaut haben. Da ist schnell klar geworden: so eine Anbindung kann man bauen, aber der Teufel steckt im Detail. Beispielsweise haben Google - oder je nachdem welche Technologie man benutzt - bestimmte Lücken, Spezial-Begriffe, die einfach nicht so häufig im Wortschatz vorkommen. Da wird schnell klar: Es muss eine Art Bibliothek geführt werden. "Dictionary", wie es jetzt heißt. Um bestimmte Aussprache-Regelungen anzupassen, bis Google selbst so weit ist.
Die Basistechnologie anzuklemmen und zu sagen, wir schicken einen Artikel raus aus dem CMS, schicken ihn an einen Service von Amazon oder Google, bekommen ein Audio File zurück und legen es irgendwo ab - das haben wir auf die Beine gestellt.
Nach weniger als zwei Wochen war aber klar: Damit ist keinem geholfen. Man hat eine Qualität. Man kann die Qualität jedoch nicht wirklich beeinflussen. Das war der Punkt, an dem wir hingen.
Bei der NZZ fand ich es sehr spannend, dass sie genau das gelauncht und direkt in ihre App integriert haben. Ich habe mich als Beta-Nutzer eingetragen und es war so unfassbar schlecht, dass ich dachte: mein Projekt ist tot. Dann bin ich irgendwann einmal wieder in die App reingegangen und die Entwicklung war enorm. Das war faszinierend. Drei Monate sind vergangen und man konnte die Qualität nicht mehr vergleichen. Ich habe dann mit dem damaligen technischen Projektleiter Kontakt aufgenommen und fand es ganz spannend, dass sie eine Halbtagskraft beschäftigt hatten. Zu diesem Zeitpunkt hatten sie schon über zehntausend Begriffe in ihrem Dictionary. Womit mir klar war: Okay, man hat einen Hebel - aber man braucht ein Dictionary.
Das Dictionary war dann ein Punkt, der intern so viele Ressourcen benötigt hätte, an dem wir gesagt haben: es wird auf jeden Fall ein dickes Brett zu bohren. Das war der Zeitpunkt, an dem wir mit euch in den Kontakt gekommen sind.
Wir haben uns auch andere Anbieter und Lösungen angeguckt. Doch was einfach ausser Frage stand: ihr seid eine Firma, die genau darauf fokussiert ist. Um diese Benutzeroberfläche zu bauen, bis man dann überhaupt betriebsbereit ist, das hätte uns minimum sechs Monate nach hinten geworfen, und Ressourcen gefressen, die wir nicht hatten.
Da war die Entscheidung relativ leicht: wir hatten zwar eine Benutzeroberfläche, die nicht nur von Programmierern bedient werden konnte und auch im Code konnten wir Regelungen für die Aussprache definieren. Man ist aber vor allem darauf angewiesen, dass Leute mithelfen und nicht eine Person allein alles macht. Wir haben inzwischen 15 Leuten, die an diesem Projekt gearbeitet haben. Leute, die Artikel angehört haben und dann Korrekturvorschläge gemacht haben. Es geht über die Masse. Eine einzelne Person den ganzen Tag nur Text-To-Speech hören zu lassen, halte ich für wenig zielführend.
Das war für mich der klare Grund zu jemanden zu gehen, der sagt: "Wir haben den Fokus darauf und wir kennen die Stellschrauben für die Verbesserung des Services".
Spannend fand ich in den ersten Gesprächen mit Dir, Andrey, dass Du noch andere Schrauben kanntest, die ich nicht kannte. Sei es, noch einmal zu prüfen welche Stimme man auswählt, kann man sie pitchen oder kann man sie leiser oder lauter machen?
Ihr hattet einen enormen Fokus auf die Verbesserung des Services, das ist bis zu dem Zeitpunkt eher selten passiert. Ich habe mich reingebohrt in dieses Thema, mit meiner "Kurz"Recherche hatte ich schon einen tierischen Wissensvorsprung vor fast allen, die ich angefragt habe. Dann stehst Du auf einmal da und sagst: "Toll, aber wenn du innerhalb von drei Wochen Experte auf diesem Gebiet geworden bist, dann kann da was nicht stimmen." Als wir in den Austausch gegangen sind, ist mir klar geworden: Es gibt jemanden, der ist noch nerdiger als ich, der hat sich da richtig reingefuchst - und er kann deutlich mehr Hebel aufzeigen als die, die mir bewusst waren.
Andrey: Warum habt ihr euch schließlich für BotTalk entschieden? Welche Auswahlkriterien gab es?
Patrick: Rückwirkend gab es keine harten, messbaren KPIs. Primär ging es hier um eine Machbarkeit, wo das Team, mit dem ich arbeite, und auch ich sagen: das ist etwas, was man sich anhören kann. Das muss schon das Ziel sein, also der Anspruch auch selbst dahinter zu stehen. Das im ersten Schritt überhaupt hinzubekommen war der erste Meilenstein.
An der Dictionary-Technologie, die BotTalk schon entwickelt hatte, war uns klar: auch wenn wir nicht scheitern, werden wir massiv Zeit verlieren. Zeit war der entscheidende Faktor, weil unser Anspruch klar war. In Deutschland, wenn nicht sogar in ganz Europa, ein 360 Grad Audio-Angebot schaffen, bei dem der Nutzer irgendwann wirklich zwischen Lesen und Hören entscheiden kann. Ohne entsprechende Qualität funktioniert das nicht.
Dann sind die Vorgespräche, die wir geführt haben, ein weiterer Faktor. Die Vision die ihr habt, in welche Richtung ihr arbeitet - das muss sich einfach mit dem decken, was wir vorhaben. Vor allem, dass ihr euch auf Publishing eingeschossen habt war sehr wichtig.
Andere Text-To-Speech Anbieter fokussieren sich auf generelle Vertonung, was sie jedoch außen vor lassen ist, dass, je nachdem aus welchem Bereich du kommst, du weitere Hürden hast. Wenn du stinknormale Webseiten vertonst, oder nehmen wir wissenschaftliche Arbeiten, dann hast du keine Twitter Codes zwischen den Artikeln, du hast auch keine "Related Articles" oder "Lesen Sie hier weiter". Das sind alles Fragmente, die du irgendwann auf der Audiospur findest, die überhaupt keinen Sinn ergeben. Das stellst du aber erst fest, wenn du es schon einmal gemacht hast. Dann ist die nächste Frage: Wie werde ich das los?
Für mich war entscheidend, dass Du in den Gesprächen gesagt hast: wir haben diesen Fokus - wir wollen der beste TTS-Anbieter für Publisher werden.
Daher ging es bei der Auswahl des Partners eher um das gemeinsame Zielbild. "Da gibt es jemanden, der ein genauso starkes Interesse hat in dem Bereich richtig gut zu werden". Harte KPIs gab es an der Stelle nicht.
Natürlich guckt man sich Erlösmodelle an und wie man das Thema monetarisieren kann. Auf klassischem Wege hat man immer zwei Modelle. Das eine sind Abo-Erlöse, die jeder Verlag kennt, und das zweite sind Werbeerlöse. So sind die Businesspläne bei uns auch aufgebaut, da dies das langfristige Ziel ist.
Du hast aber ganz viele andere Hürden, die du vorher nehmen musst.
Wenn du ein Produkt entwickelst, von dem du sagst, du würdest es selbst nicht nutzen - dann brauchst du über Monetarisierung nicht nachzudenken.
Um den Automatisierungsgrad herzustellen, um überhaupt dahin zu kommen, dass du die Produkte, auf denen Audio ausgespielt wird, so designst, dass Leute das überhaupt nutzen wollen - das sind alles Hürden auf dem Weg gewesen. Für mich war klar, der Kern ist erst einmal eine Audioqualität zu haben, bei der du sagst: "Haken dran. Höre ich mir an. Ist vielleicht noch ein bisschen holprig".
Aber es ging um das Potenzial, wohin es gehen kann. Das war mein KPI - und ein sehr vager.
Andrey: Was ist dir bei der Zusammenarbeit mit Technologie-Partnern wichtig?
Patrick: Ich kann nicht generell für Technologie-Projekte sprechen. Ich habe davon in meinem Leben einige geleitet. Manchmal sind es einfache Produktverbesserungen oder Weiterentwicklungen, dafür gibt es Spezialisten, vor allem in gesetzten Feldern. Was man sich in unserem Falle anschauen muss ist, dass man in einem Feld unterwegs ist, das es nicht gibt. Wie ich eingangs schon sagte, habe ich mich drei bis vier Wochen mit dem Thema Text-To-Speech beschäftigt und hatte teilweise Anbietern gegenüber einen Wissensvorsprung.
Dieses Feld ist so neu, dass man andere Messkriterien für Technologie-Partner anlegen muss. Vor allem geht es um das Vertrauen in die Personen die dahinter stehen - oder in diesem Fall - in Dich als Gründer, die treibende Kraft, und in die Vision, die eine Firma hat.
Es geht um ein sehr großes Vertrauen darin, dass man gemeinsam ein Ziel erreicht von dem beide heute noch nicht einmal wissen, wie es überhaupt aussieht. Das ist im Nachhinein einfach zu sagen, weil unser Projekt jetzt fortgeschritten ist. Wir werden immer klarer darin wohin wir wollen. Ich kann nicht behaupten, dass wir das vor einem Jahr wussten. Es geht bei der Auswahl von Partnern einfach darum, dass vor allem die Idee, wohin es sich entwickeln soll, da ist. Und das Zielbild muss matchen. Plus das Engagement, welches der Technologiepartner reinbringt - und auch eigene Ideen.
Worauf ich überhaupt keine Lust habe ist es Anbieter zu wählen, die abarbeiten. Dann hast du einen Katalog, ein Pflichtenheft - und das wird halt weggearbeitet.
Das funktioniert aber nicht in einem Markt, der so neu ist. Das ist das wichtigste Entscheidungskriterium, weshalb wir mit euch arbeiten. Weshalb wir beispielsweise auch auf einen Anbieter - mit dem wir eine zentrale Audio-Plattform bauen - gesetzt haben, mit dem wir seit vier Jahren erfolgreich im Videobereich arbeiten. Es ging auch da um die gemeinsame Vision: sie haben erkannt, dass der Audio-Markt riesig wachsen wird.
Neben Video, was schon eine große Einnahmequelle ist, ist Audio einfach etwas, was noch nicht stringent bedient wird.
Das finde ich sehr spannend, da mit Audio, abseits von Musik, schlichtweg nie Geld zu verdienen war. Podcast ist das erste Mal, dass die Leute merken "Da passiert ja was!"
Wenn man über Audio spricht ist Text-To-Speech noch ein bisschen weiter hinten und stiefmütterlich behandelt. Die schöne glitzernde Front ist der Podcast und das stößt ganz viele Türen auf. Doch ich glaube Audio hat viel mehr zu bieten als nur Podcast.
Beides hat seine Daseinsberechtigung und bedient verschiedene Bereiche. Beispielsweise: mit einem tagesaktuellen Podcast hast du einen unfassbaren Aufwand. Was vielen nicht klar ist, dass bei Formaten wie "Steingart", die immer ganz vorne gehalten werden, in der Redaktion vier bis acht Leuten dahinter sitzen, die jeden Tag arbeiten.
Deshalb ergänzen sich diese Technologien oder diese Content-Formen hervorragend, weil man mit Text-To-Speech tagesaktuell vertonen kann, und das zu einem unter-humanen Preis. Du kannst große Mengen Content schieben.
Ich finde es nur wichtig zu verstehen, dass du zwei unterschiedliche Nutzerbedürfnisse dahinter hast. Das eine sind in der Regel qualitative Stücke, bei denen ich mir bewusst Zeit nehme um sie mir anzuhören. Und beim anderen steht der nachrichtliche Informationswert im Vordergrund. Da interessiert mich die Qualität der Stimme nur bedingt. Der Informationswert steht weiter oben.
Das, was die drastische Veränderungen bringen wird, ist Text-To-Speech, nicht Podcasts. Aber Podcasts machen die Tür auf.
Andrey: Warum ist der Einsatz von BotTalk für euch so einfach?
Patrick: Ob bei Podcasts oder auch bei Text-To-Speech: die Einstellung "Ich mach' mal nebenbei mit" - bitte gleich vergessen und gar nicht erst anfangen. Das ist ganz wichtig.
Man braucht Engagement. Man braucht jemanden der sich darum kümmert. Wie Sachen technisch integriert werden, wie Schnittstellen funktionieren. Du brauchst Leute, die die Qualität überwachen. Du klemmst nicht irgendwas an und und wie durch Magie können auf einmal Namen von Lokalpolitikern, die außerhalb von Flensburg kein Mensch kennt, korrekt ausgesprochen werden.
Das ist vielleicht in zehn Jahren so, wenn die Datenbanken groß genug sind. Das heißt, man braucht schon Leute, die da engagiert reingehen.
Dadurch, dass wir mit BotTalk arbeiten, hatten wir ein Time-to-Market Vorsprung. Das ist ganz essenziell, auch für jeden anderen der darüber nachdenkt. Du kannst relativ schnell ausrollen. Und dann kommt der ganz wichtige Part: du musst den Nutzern zuhören und kontinuierlich weiter daran arbeiten.
Wir haben diverse Schnittstellen-Anpassungen gemacht, um besser beurteilen zu können, was die Kunden hören wollen. Oder die Text-To-Speech Korrektur, die wir zusammen entwickelt haben.
Mit BotTalk hast du eine Oberfläche, in der du einen Beitrag hörst, danach bewertest und kategorisierst. Zu Höchstzeiten hatten wir 15 Leute, die jeden Tag Artikel gehört und Korrekturen eingespielt haben. Und das ist essenziell: um ein Gefühl dafür zu bekommen, wie gut die Qualität ist.
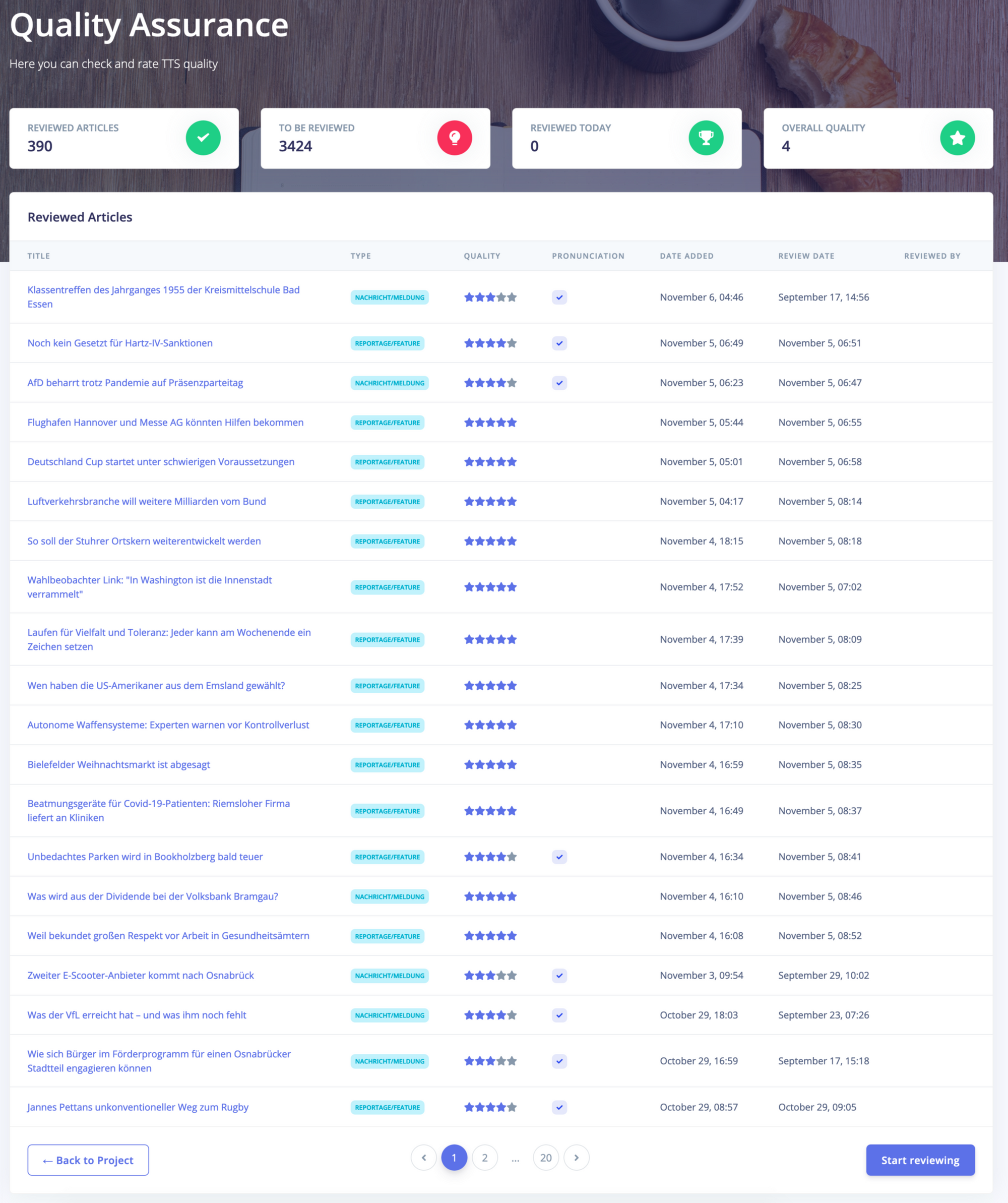
Wir hatten sehr viele Unterhaltung darüber, ob mit der Automatisierung das Gefühl einhergeht, die Kontrolle verloren zu haben. Aktuell werden 90 % unserer Inhalte durch BotTalk vertont. Das kann kein Mensch mehr hören. Da braucht man sich nichts vormachen, das geht nicht. Die Kontrolle ist mit euch möglich, mit einem Feature, das wir gemeinsam entwickelt haben. Es gibt eine Benutzeroberfläche, in der du zumindest einen Bruchteil des Contents hören kannst und die dir Feedback gibt: verbessert sich die Qualität oder verschlechtert sie sich?
BotTalk bietet eine Möglichkeit die Qualität im Griff zu haben und stetig zu verbessern. Ich habe das intern alles schätzen lassen, was es kosten würde all das zu bauen und vor allem - wieder Time to Market - wie lange es dauern würde. Und das ist absurd! Es macht keinen Sinn es selber zu bauen.
Das ist für mich eigentlich der entscheidende Punkt: Time to Market. Und mit Dir, Andrey, habe ich jemanden, der mir immer wieder zeigen kann: wo kann man noch besser werden? Das ist für mich der Schlüssel.
Andrey: Wie siehst du die Zukunft von TTS im Publishing?
Patrick: Ich glaube nicht, dass irgendein Publisher drum herum kommen wird. Das ist meine ehrliche und einfache Meinung.
Das ist eine Technologie, die noch in den Kinderschuhen steckt. Ich hatte ja meinen ersten Eindruck vom Produkt der NZZ. Ich habe mich gefragt, wie sie sich getraut haben das zu veröffentlichen. Drei Monate später gehe ich wieder rein und sehe die respektable Verbesserung.
Das ist unfassbar. Seitdem wir mit BotTalk arbeiten, gab es zwei große Anpassungen. Neben der Tatsache, dass WaveNet selbst noch einmal etwas nachgeschoben hat, habt ihr an zwei, drei Schrauben gedreht und innerhalb von zwei Tagen hat sich die Sprachqualität gefühlt um 20% verbessert.
Das erzähle ich jedem, mit dem ich über das Thema spreche. Ich glaube, dass, wenn wir uns in einem Jahr unterhalten, die meisten unserer Kunden - speziell die älteren - nicht mehr zwischen einer menschlichen und einer synthetisch erzeugten Stimme unterscheiden werden können. Das wird einfach nicht mehr möglich sein.
Dass das geht, zeigen mir die Verbesserungen, die allein in diesem kurzen Zeitraum stattgefunden haben. In der Regel ist die Entwicklung bei Technologien exponentiell und nicht linear. In der deutschen Sprache wird es im nächsten, spätestens im übernächsten Jahr kommen. In der englischen Sprache kann man das heute schon hören.
Google hat die WaveNet-Technologie auf eine Webseite gepackt, bei der du einen echten Sprecher und Text-To-Speech hörst. Du musst raten: was ist der Sprecher, was ist TTS - und du kriegst es nicht hin!
Die englische Sprache hat jetzt schon eine größere Datengrundlage, weil sie einfach in viel mehr Ländern auf der Welt gesprochen wird. Im Deutschen ist das noch nicht so. Doch je mehr die Technologie eingesetzt werden, desto schneller lernen diese Services.
Für mich steht außer Frage, dass wir zu dem Punkt kommen, an dem sich TTS menschlich anhört. Und zwar so sehr, dass das Gehirn es nicht mehr auseinander hält.
Ab diesem Zeitpunkt stelle ich mir die Frage: wie kann man denn drum herumkommen, wenn das Nutzerverhalten zeigt: Audio ist der Nummer Eins Kanal.
Wir sehen zeitgleich Trends, wie Second Screen Verhalten - also während des Fernsehguckens das Smartphone zu bedienen. Oder eine parallele Nutzung: joggen gehen und dabei Podcast hören. Diese Trends werden immer stärker in unserer Gesellschaft - und da bist du mit Text geliefert! Du kannst nicht joggen und lesen, alleine nebenbei WhatsApp schreiben ist schon schwierig genug. Du wirst also keine Artikel lesen während du joggst, das wird einfach nicht passieren.
Der essenzielle Punkt, weshalb so etwas wie eine Print-Zeitung noch immer lebt, sind Routinen. Die sind in uns eingebrannt, über Jahrzehnte. Ich lese die Zeitung in der Straßenbahn, oder ich sitze beim Frühstück und lese Zeitung. Das alles sind Sachen, da gewöhnen sich Menschen dran. Und bis zu 90 % unseres Tages sind von Routinen bestimmt. Nicht vom Bewussten, sondern von routinierten Tagesabläufen.
Ich glaube, dass über das Hören neue Routinen erschlossen und erobert werden können. Durch Publisher. Dort, wo sie nie mit einem textbasierten Produkt reinkommen. Das sind die Klassiker, die in unseren Umfragen immer wieder genannt worden sind: Pendeln, Autofahren, Haushalt, Kochen, Bügeln. Und die Morgenroutine, die ich für einen absoluten Schlüssel halte. Im Bad - wie soll ich in einer Zeitung lesen, beim Zähneputzen oder Duschen? All das geht mit Audio!
Das ganz große Bild - wenn du das weiter spinnst - ist tatsächlich, dass wenn wir unseren gesamten Audio Inhalt gut hörbar zur Verfügung stellen, eine Informationsmenge haben, die die des Radios übersteigt. Und das ist, was viele, glaube ich, so bis jetzt nicht gesehen haben. Weil sie die Technologie noch nicht richtig auf dem Schirm haben.
Ab dem Moment, wo TTS gut klingt und du die Stimme nicht mehr unterscheiden kannst, du monatlich zwanzigtausend Artikel schreibst, mit einer durchschnittlichen Hördauer von dreieinhalb Minuten: dann hast du auf einmal das Sendevolumen von zwei Radiosendern. Und dabei wiederholt sich keine einzige Nachricht!
Das ist massiv. Und ich glaube, dass da wirklich eine ganz neue Medienbranche oder ein Medienzweig aufgehen wird, der sich tatsächlich irgendwo zwischen Radio und Zeitung bewegen wird. Der riesige Vorteil für Publisher im Textbereich ist - und was auf den ersten Blick vielleicht nachteilig wirken mag - wir haben kein technologisches Erbe, wir sind beispielsweise nicht an Rundfunklizenzen gebunden.
Das heißt, wir setzen von Anfang an auf On-Demand Technik. Wir haben Nutzer in bestehenden Produkten, in die Audio wirklich gut integriert werden kann, in Mobilfunk Anwendungen oder auf dem iPad.
Wir können hyperlokale und auch überregionale Nachrichten ausspielen, die hörbar sind. Das heißt, du hast den nachrichtlichen Sektor abgedeckt und eroberst die Audiowelt.
Und dann ergeben sich ganz viele spannende, neue Fragen: macht es nicht Sinn auch Musik zu integrieren? Ab dem Moment kann mit Playlisten, die automatisiert zusammengestellt werden, experimentiert werden. Auf einmal entsteht eine völlig neue Mediengattung!
Von daher stellt sich diese Frage für mich nicht: Ich glaube nicht, dass irgendein Publisher drum herum kommen wird TTS zu integrieren.